# Libraries
library(arules)
library(tidyverse)
# Importing the dataset
movies <- read.csv("https://raw.githubusercontent.com/DataKortex/Data-Sets/refs/heads/main/Datacamp_public_datasets/movies.csv")Market Basket Analysis
Introduction
When browsing a product on an online marketplace (say Amazon), we’re often shown a list of recommended items. For example, after adding a laptop to the cart, we might be presented with suggestions for a mouse, a keyboard, or a laptop sleeve. A similar experience happens on platforms like Netflix or Disney Plus. Watching a movie often triggers recommendations for other titles with related themes or genres. If we watch the first The Lord of the Rings film, the sequel is likely to appear next.
It is not difficult to understand that these suggestions are anything but random. They’re powered by algorithms that learn from user behavior and preferences, in order to offer relevant recommendations (Schafer, Konstan, & Riedl, 2001; Adomavicius & Tuzhilin, 2005).
One of the most widely used techniques behind the generation of such recommendations is Market Basket Analysis. The core idea is simple: identify relationships between items that are frequently purchased together (Tan, Steinbach, & Kumar, 2019). In technical terms, we look for association rules—patterns like “if a customer buys product A, they’re also likely to buy product B”. These rules help businesses understand customer behavior and, therefore, improve cross-selling strategies.
Association Rules and Probability
In simple terms, an association rule shows that the purchase of one product increases the probability of purchasing another. For example, if many customers who buy product A also go on to buy product B, we can express this relationship as:
\[\{ \text{Product A} \} \Rightarrow \{ \text{Product B} \}\]
This reads as: “If product A is purchased, then product B is also likely to be purchased.” In other words, sale of product A implies sale of product B.
From a probability standpoint, association rules represent conditional probabilities. That means we’re interested in the probability that one event (e.g., buying product B) occurs, given that another event (e.g., buying product A) has already happened; we discussed how conditional probabilities apply to dependent events in Chapter Naive Bayes.
Here, each purchase is considered an event, and we want to know how the purchase of one product influences the probability of purchasing another. Mathematically, this is written as:
\[P(B \mid A)\]
We estimate this probability by checking how often product B is bought when product A has been bought. For instance, if 8 out of 10 customers who purchase product A subsequently purchase product B, we estimate the (conditional) probability of “B given A” as 80%.
In many cases though, we need to visit more complex situations, such as how likely a customer is to buy product C given that they have already bought both product A and product B:
\[\{ \text{Product A, Product B} \} \Rightarrow \{ \text{Product C} \}\]
\[P(C \mid A, B)\]
As we start considering combinations of multiple products, the number of possibilities increases dramatically. For example, if a store offers 1,000 different products, there are 499,500 unique product pairs, and even more combinations when considering three or more items. Analyzing every possible combination would be computationally overwhelming and unnecessary, since many product combinations are irrelevant (for example, laptops and bicycles are rather unlikely to be selected for the same purchase transaction).
To deal with this complexity, we rely on smart algorithms, designed to filter out the noise and focus only on meaningful product combinations. One of the most popular algorithms for this task is the Apriori algorithm (Agrawal & Srikant, 1994), which is the approach we will use in this chapter.
Before we move on, it’s important to distinguish between market basket analysis and the Apriori algorithm. Market basket analysis is a data mining technique, its goal being to uncover association rules in transaction data. The Apriori algorithm, on the other hand, is a machine learning tool that helps us efficiently find such associations by calculating respective probabilities and filtering the results. In short, Apriori is one way to implement market basket analysis in practice.
Terminology and Assumptions
Before diving into the Apriori algorithm in R, we need to clarify a few key terms and assumptions used in market basket analysis. Imagine observing customers at a supermarket checkout line. Each person holds a basket filled with items they’ve chosen. Some baskets might contain similar products, while others look completely different. In this setting, the contents of a single basket represent what we call an itemset, which is simply a group of items purchased simultaneously (Agrawal, Imieliński, & Swami, 1993).
In market basket analysis, we also use the term transaction. A transaction corresponds to a single shopping event—typically the set of items a single customer buys at one time. In our supermarket example, each basket is one transaction. Thus, the number of transactions equals the number of baskets we observe. This terminology is important because in practice we work with transactional data: a dataset where each row corresponds to one transaction (one basket), and the Apriori algorithm searching across all transactions to find frequent itemsets and association rules.
Respectively, let us focus on the main assumptions behind market basket analysis. While we could work around those assumptions depending on the question we want to ask, they help us start with and clarify the fundamentals and, at the same time, shape how we interpret and work with the data:
Quantity of a unit doesn’t matter: We don’t consider how many units of an item a customer buys. Whether someone purchases one can of milk or three, we treat it the same—we’re only interested in whether the item was bought (or not).
All items are treated equally: Every product is considered distinct, even if two items are very similar. For example, two different brands of toothpaste are treated just like two completely different products, such as bread and toothpaste; we don’t group items based on how similar they are.
Customers are open to recommendations: When we recommend product B because a customer has purchased product A, we assume the customer hasn’t already rejected product B. In other words, the association rule \({A} \Rightarrow {B}\) is only valuable if the customer is still open to buying B. This assumption is essential for the effectiveness of market basket analysis in real-world recommendation systems.
Understanding these assumptions helps us better interpret the results we get from the algorithm and gives us a solid foundation before we move on to implementation.
Applying the Apriori algorithm in R
To apply the Apriori algorithm, we start by importing the movies dataset and loading the arules package. The movies dataset is available on GitHub and consists of 5 columns (fields) and 17,575 rows (movies) that 100 users watched in an online platform. The 5 columns are as follows:
User_ID: ID number of the person that watched the movieMovie_ID: ID number of the movieTitle: Title of the movieYear: Release year of the movieGenres: Movie category
We load the arules package, along with the tidyverse package which we will need later, and the movies dataset using the following code:
The key pieces of information we need for Market Basket Analysis are the column that identifies the customer and the column that lists the products purchased. These are the main variables used to build association rules. After importing the data, we use the function split() to create a list that contains the two mentioned variables (Title and User_Id). After the split() function, we transform the created list to “transactions” form using the function as():
# Applying the split() function on movies
movies_list <- split(movies$Title, movies$User_ID)
# Transforming movies_list to transactions
movies_tr <- as(movies_list, "transactions")Warning in asMethod(object): removing duplicated items in transactions# Printing the structure of movies_tr
str(movies_tr)Formal class 'transactions' [package "arules"] with 3 slots
..@ data :Formal class 'ngCMatrix' [package "Matrix"] with 5 slots
.. .. ..@ i : int [1:19048] 16 19 21 26 27 28 29 30 31 37 ...
.. .. ..@ p : int [1:101] 0 987 1127 1536 1599 2027 2065 2190 2217 2567 ...
.. .. ..@ Dim : int [1:2] 4382 100
.. .. ..@ Dimnames:List of 2
.. .. .. ..$ : NULL
.. .. .. ..$ : NULL
.. .. ..@ factors : list()
..@ itemInfo :'data.frame': 4382 obs. of 1 variable:
.. ..$ labels: chr [1:4382] "'burbs, The" "(500) Days of Summer" "(Untitled)" "*batteries not included" ...
..@ itemsetInfo:'data.frame': 100 obs. of 1 variable:
.. ..$ transactionID: chr [1:100] "1323" "1913" "2029" "3699" ...When running the code, a warning is printed that duplicate items (movie titles in this case) have been removed. This happens because we’re using the Title column instead of the Movie_ID column. While some movies share the same title, they are actually different films. For example, King Kong has been released multiple times, in 1933, 1976, and 2005, with each version having a different Movie_ID. By using the Title column, we treat all movies with the same name as if they are actually the same, even though they are not. We do this for simplicity and better readability of the Apriori algorithm’s output, as it is easier to interpret the results (from a human perspective) when we see recognizable movie names rather than numeric IDs. However, this means that if a customer has watched both the 1933 and 2005 versions of King Kong, the algorithm treats it as a duplicate and only keeps one of them.
To get a better understanding of our output, we can use the summary() function to get an overview of its contents:
# Summary
summary(movies_tr)transactions as itemMatrix in sparse format with
100 rows (elements/itemsets/transactions) and
4382 columns (items) and a density of 0.04346874
most frequent items:
Matrix, The American Beauty Fight Club
60 57 54
Silence of the Lambs, The Shawshank Redemption, The (Other)
50 48 18779
element (itemset/transaction) length distribution:
sizes
20 22 23 24 25 26 27 28 35 36 38 39 40 43 46 47
2 1 3 3 1 2 2 1 1 1 1 2 1 1 1 1
48 50 53 54 55 58 59 62 63 66 68 69 72 73 76 77
1 1 3 1 1 1 1 1 1 1 1 1 1 2 1 1
81 84 89 93 99 118 119 125 126 128 131 134 136 140 145 151
1 2 3 1 1 1 2 2 1 1 1 1 1 2 2 1
153 165 177 181 195 197 198 199 206 228 231 232 236 240 252 263
1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1
267 295 325 350 355 376 378 390 409 428 436 585 985 987 1351 1436
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1493
1
Min. 1st Qu. Median Mean 3rd Qu. Max.
20.0 49.5 96.0 190.5 211.5 1493.0
includes extended item information - examples:
labels
1 'burbs, The
2 (500) Days of Summer
3 (Untitled)
includes extended transaction information - examples:
transactionID
1 1323
2 1913
3 2029There are 100 transactions (users) and 4382 items (movies).The most frequent movies that were watched are The Matrix, American Beauty, Fight Club and The Silence of the Lambs. The movie The Matrix was watched by 60 users while the American Beauty was watched by 57. Below, we also see the distribution of the transactions (or how “big” a “basket” was). For example, the two least active users watched 20 movies while the most active user watched 1493.
Visualizing Frequencies
The arules package provides the function itemFrequencyPlot(), which is useful for visualizing the most frequently watched movies (e.g., the top 10). However, we can perform the same type of exploratory data analysis using ggplot2 directly on the original tibble.
To construct this type of plot, we can build on the data manipulation and visualization techniques introduced in Chapter Data Manipulation and Chapter Data Visualization with ggplot2. First, we use the count() function with the argument sort to TRUE to compute the number of users per movie and sort the results in descending order. Then, we use slice() to retain only the top 10 movies. Finally, we create the plot using ggplot() with geom_col(), mapping the counts to the y-axis:
movies %>%
count(Title, sort = TRUE) %>%
slice(1:10) %>%
ggplot(aes(x = Title, y = n)) +
geom_col(color = "black",
fill = "skyblue") +
labs(x = "",
y = "Number of Users")
Although this plot contains the correct information, it is not easy to interpret. First, even though the tibble is sorted, the movies on the x-axis are displayed in alphabetical order rather than by their frequency. Second, the movie titles overlap, making them difficult to read.
To address the first issue, we can use the fct_reorder() function from the forcats package (part of the tidyverse). This function reorders a categorical variable based on the values of another variable. In this case, we reorder Title based on the counts (n), which determines the order in the plot.
For the second issue, we can use the function coord_flip() to swap the x- and y-axes. This is particularly helpful when working with long category labels, as it makes the plot easier to read.
With these adjustments, the plot becomes much clearer:
movies %>%
count(Title, sort = TRUE) %>%
slice(1:10) %>%
mutate(Title = fct_reorder(.f = Title, .x = n)) %>%
ggplot(aes(x = Title, y = n)) +
geom_col(color = "black",
fill = "skyblue") +
labs(x = "",
y = "Number of Users") +
coord_flip()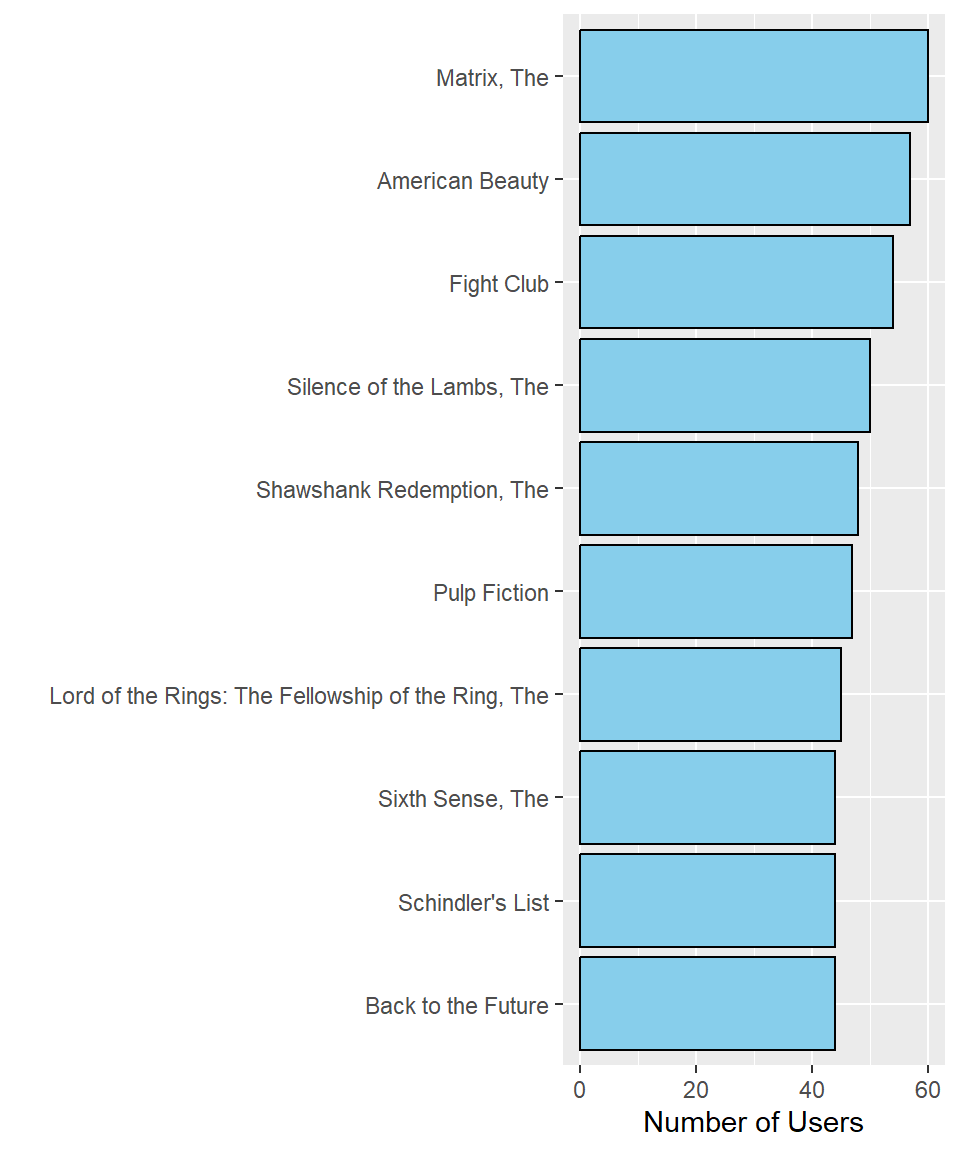
This plot is now much easier to read. The most-watched movie is The Matrix, with 60 users, followed by American Beauty and Fight Club. Additionally, The Sixth Sense, Schindler’s List, and Back to the Future were all watched by the same number of users.
Using the same approach, we can create similar frequency plots for other aspects of the dataset, such as the number of movies watched per user.
Support and Confidence
Two main characteristics guide market basket analysis: how often a product appears in the entire dataset, and how often one product appears after another one has already been selected. These are known as support and confidence, respectively.
Support is defined as the frequency an itemset occurs within all transactions (how much it is “supported”). Simply put, support tells us in how many baskets a product, or a combination of products, appears:
\[\text{Support(X)} = \frac{\text{Frequency(X)}}{N}\]
where \(X\) is an itemset and \(N\) is the number of transactions (or customers) the product appears. Essentially, support represents the probability that itemset \(X\) appears in a randomly selected basket:
\[\text{Support(X)} = P(X)\]
Confidence measures the strength of an association rule and is defined as the support of the combined itemset (\(X\), \(Y\)) divided by the support of \(X\) alone (how much confidence we have that product \(Y\) is also chosen given product \(X\) has been chosen). In other words, it is the conditional probability that product \(Y\) is purchased given that product \(X\) was purchased.
\[\text{Confidence}(X \to Y) = \frac{\text{Support}(X, Y)}{\text{Support}(X)} = \frac{\text{Frequency}(X, Y)}{\text{Frequency}(X)}\]
Mathematically, we have:
\[\text{Confidence}(X➔Y) = P(Y|X)\]
Note that confidence is directional: the confidence of \(X \to Y\) is different from \(Y \to X\), as the denominator differs.
Both support and confidence range between 0 and 1, as they represent probabilities. They form the basis for generating association rules, which are filtered using threshold values defined in advance. For example, we may choose to ignore rules involving products that are rarely purchased, by setting a minimum support. In this way, support and confidence also act as hyperparameters in market basket analysis.
To illustrate how this works, we will use the function apriori() from the arules package in R. This function requires a transaction data object (data_tr) and a list of parameters specifying our conditions for analysis. Suppose we want to find all itemsets with at least 30% support and containing at least three products (or movies in our example). Since we are interested in the frequency of these itemsets and not yet the association rules themselves, we set the parameter target to "frequent itemsets". Using the following code, we produce an object called itemsets:
# Applying the Apriori algorithm - Item frequency (support)
itemsets <- apriori(movies_tr,
parameter = list(
support = 0.3,
minlen = 3,
target = "frequent itemsets"))To examine the results, we use the function inspect():
# Inspecting the results
inspect(itemsets) items support count
[1] {Lord of the Rings: The Fellowship of the Ring, The,
Lord of the Rings: The Return of the King, The,
Lord of the Rings: The Two Towers, The} 0.35 35
[2] {Lord of the Rings: The Return of the King, The,
Lord of the Rings: The Two Towers, The,
Matrix, The} 0.31 31
[3] {Lord of the Rings: The Fellowship of the Ring, The,
Lord of the Rings: The Return of the King, The,
Matrix, The} 0.31 31
[4] {Lord of the Rings: The Fellowship of the Ring, The,
Lord of the Rings: The Two Towers, The,
Matrix, The} 0.33 33
[5] {Jurassic Park,
Matrix, The,
Silence of the Lambs, The} 0.30 30
[6] {Matrix, The,
Star Wars: Episode IV - A New Hope,
Star Wars: Episode V - The Empire Strikes Back} 0.34 34
[7] {Fight Club,
Lord of the Rings: The Fellowship of the Ring, The,
Matrix, The} 0.30 30
[8] {American Beauty,
Pulp Fiction,
Silence of the Lambs, The} 0.31 31
[9] {American Beauty,
Fight Club,
Pulp Fiction} 0.30 30
[10] {American Beauty,
Matrix, The,
Pulp Fiction} 0.30 30
[11] {Pulp Fiction,
Shawshank Redemption, The,
Silence of the Lambs, The} 0.31 31
[12] {Fight Club,
Pulp Fiction,
Silence of the Lambs, The} 0.34 34
[13] {Matrix, The,
Pulp Fiction,
Silence of the Lambs, The} 0.32 32
[14] {Fight Club,
Matrix, The,
Pulp Fiction} 0.30 30
[15] {Back to the Future,
Matrix, The,
Raiders of the Lost Ark (Indiana Jones and the Raiders of the Lost Ark)} 0.30 30
[16] {Forrest Gump,
Matrix, The,
Silence of the Lambs, The} 0.31 31
[17] {Back to the Future,
Matrix, The,
Star Wars: Episode IV - A New Hope} 0.31 31
[18] {Fight Club,
Matrix, The,
Silence of the Lambs, The} 0.30 30
[19] {Lord of the Rings: The Fellowship of the Ring, The,
Lord of the Rings: The Return of the King, The,
Lord of the Rings: The Two Towers, The,
Matrix, The} 0.31 31The items column reflects the different itemsets found (e.g., the three Lord of the Rings movies), along with the columns support and count. These represent, respectively, the support (i.e., the probability) and the frequency (i.e., raw count) of each itemset. In essence, the count column is just the numerator of the support calculation. Note that the inspect() function does not produce a tibble, so we cannot easily use this output for further analysis or visualization.
Since we have 100 users in our dataset, it’s easy to verify that support is calculated by dividing the frequency of an itemset by the total number of users. For example, the itemset with the highest support is the Lord of the Rings trilogy: 35 users (or 35% of all users in our dataset) watched all three movies. While it is intuitive that these three movies would frequently appear together, we haven’t created any (association) rules yet. Thus, we still don’t know, for instance, the probability that a user who watched the first movie also watched the second.
To generate association rules, we change the target parameter to "rules". Let us also set the conf argument (which refers to the minimum required confidence) to 0.9, so as to emphasize only strong relationships:
# Applying the Apriori algorithm - Rules
rules_movies <- apriori(movies_tr,
parameter = list(
support = 0.3,
conf = 0.9,
minlen = 3,
target = "rules"))The object we created (rules_movies) contains all potential association rules. While we could use the inspect() function to view the output, it does not return a data frame. However, having the output in data frame format is preferable, as it allows us to analyze the rules more effectively, decide which ones to keep, and make further modifications if needed.
We want the first two columns to be shown based on the statement: “If customer selects itemset \(X\) {Column 1}, then the customer will select itemset \(Y\) {Column 2}”.
Based on this logic, itemset \(X\) should appear on the left-hand side (lhs) and itemset \(Y\) on the right-hand side (rhs) in a two-column data frame. To extract these columns from the rules_movies object, we use the labels(), lhs(), and rhs() functions as follows:
# Extract itemset X
itemset_X <- labels(lhs(rules_movies))
# Extracting itemset Y
itemset_Y <- labels(rhs(rules_movies))
# Printing itemset_X
itemset_X [1] "{Lord of the Rings: The Return of the King, The,Lord of the Rings: The Two Towers, The}"
[2] "{Lord of the Rings: The Fellowship of the Ring, The,Lord of the Rings: The Return of the King, The}"
[3] "{Lord of the Rings: The Fellowship of the Ring, The,Lord of the Rings: The Two Towers, The}"
[4] "{Lord of the Rings: The Return of the King, The,Matrix, The}"
[5] "{Lord of the Rings: The Two Towers, The,Matrix, The}"
[6] "{Lord of the Rings: The Return of the King, The,Matrix, The}"
[7] "{Lord of the Rings: The Two Towers, The,Matrix, The}"
[8] "{Jurassic Park,Silence of the Lambs, The}"
[9] "{Star Wars: Episode IV - A New Hope,Star Wars: Episode V - The Empire Strikes Back}"
[10] "{Matrix, The,Star Wars: Episode V - The Empire Strikes Back}"
[11] "{Fight Club,Pulp Fiction}"
[12] "{Fight Club,Silence of the Lambs, The}"
[13] "{Back to the Future,Raiders of the Lost Ark (Indiana Jones and the Raiders of the Lost Ark)}"
[14] "{Forrest Gump,Silence of the Lambs, The}"
[15] "{Back to the Future,Star Wars: Episode IV - A New Hope}"
[16] "{Lord of the Rings: The Return of the King, The,Lord of the Rings: The Two Towers, The,Matrix, The}"
[17] "{Lord of the Rings: The Fellowship of the Ring, The,Lord of the Rings: The Return of the King, The,Matrix, The}"
[18] "{Lord of the Rings: The Fellowship of the Ring, The,Lord of the Rings: The Two Towers, The,Matrix, The}" # Printing itemset_Y
itemset_Y [1] "{Lord of the Rings: The Fellowship of the Ring, The}"
[2] "{Lord of the Rings: The Two Towers, The}"
[3] "{Lord of the Rings: The Return of the King, The}"
[4] "{Lord of the Rings: The Two Towers, The}"
[5] "{Lord of the Rings: The Return of the King, The}"
[6] "{Lord of the Rings: The Fellowship of the Ring, The}"
[7] "{Lord of the Rings: The Fellowship of the Ring, The}"
[8] "{Matrix, The}"
[9] "{Matrix, The}"
[10] "{Star Wars: Episode IV - A New Hope}"
[11] "{Silence of the Lambs, The}"
[12] "{Pulp Fiction}"
[13] "{Matrix, The}"
[14] "{Matrix, The}"
[15] "{Matrix, The}"
[16] "{Lord of the Rings: The Fellowship of the Ring, The}"
[17] "{Lord of the Rings: The Two Towers, The}"
[18] "{Lord of the Rings: The Return of the King, The}" We now have two vectors: itemset_X, containing the left-hand side itemsets, and itemset_Y, containing the corresponding right-hand side itemsets. Each entry represents a rule in the form of “if X, then Y”.
Next, we extract the associated metrics (such as support and confidence) from the rules_movies object using the @ operator and accessing the quality slot, which is simply a component of the rules_movies object that contains a data frame with one row per rule and one column for each measure:
# Extracting metrics
metrics <- rules_movies@qualityFinally, we combine all extracted components into one tidy data frame using tibble() and bind_cols() as shown below:
# Combining the outputs in one tibble
output <- tibble(lhs = itemset_X,
rhs = itemset_Y) %>%
bind_cols(metrics)
# Printing output
output# A tibble: 18 × 7
lhs rhs support confidence coverage lift count
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <int>
1 {Lord of the Rings: The Return… {Lor… 0.35 1 0.35 2.22 35
2 {Lord of the Rings: The Fellow… {Lor… 0.35 1 0.35 2.63 35
3 {Lord of the Rings: The Fellow… {Lor… 0.35 0.921 0.38 2.56 35
4 {Lord of the Rings: The Return… {Lor… 0.31 1 0.31 2.63 31
5 {Lord of the Rings: The Two To… {Lor… 0.31 0.939 0.33 2.61 31
6 {Lord of the Rings: The Return… {Lor… 0.31 1 0.31 2.22 31
7 {Lord of the Rings: The Two To… {Lor… 0.33 1 0.33 2.22 33
8 {Jurassic Park,Silence of the … {Mat… 0.3 0.909 0.33 1.52 30
9 {Star Wars: Episode IV - A New… {Mat… 0.34 0.944 0.36 1.57 34
10 {Matrix, The,Star Wars: Episod… {Sta… 0.34 0.944 0.36 2.15 34
11 {Fight Club,Pulp Fiction} {Sil… 0.34 0.919 0.37 1.84 34
12 {Fight Club,Silence of the Lam… {Pul… 0.34 0.919 0.37 1.96 34
13 {Back to the Future,Raiders of… {Mat… 0.3 0.938 0.32 1.56 30
14 {Forrest Gump,Silence of the L… {Mat… 0.31 0.939 0.33 1.57 31
15 {Back to the Future,Star Wars:… {Mat… 0.31 0.939 0.33 1.57 31
16 {Lord of the Rings: The Return… {Lor… 0.31 1 0.31 2.22 31
17 {Lord of the Rings: The Fellow… {Lor… 0.31 1 0.31 2.63 31
18 {Lord of the Rings: The Fellow… {Lor… 0.31 0.939 0.33 2.61 31Lift and Defining Association Rules
Setting the target argument to "rules", generates three additional columns: confidence, lift, and coverage. As previously discussed, confidence represents the conditional probability that the itemset on the right-hand side (consequent) is selected, given that the itemset on the left-hand side (antecedent) is selected. Coverage refers to the proportion of transactions in which both the antecedent and the consequent appear together. In simpler terms, it reflects how frequently both itemsets co-occur in the dataset and is effectively the support metric of the combined itemset. Lift, finally, is a particularly informative metric. Lift is defined as the support of the joint itemset (\(X\), \(Y\)) divided by the product of the individual supports of \(X\) and \(Y\). It quantifies how much more likely item \(Y\) is to be purchased given that item \(X\) is already purchased, relative to the overall probability of purchasing \(Y\).
The formula for lift is as follows:
\[\text{Lift}(X \to Y) = \text{Lift}(Y \to X) = \frac{\text{Support}(X, Y)}{\text{Support}(X) \times \text{Support(Y)}} = \frac{\text{Frequency}(X, Y)}{\text{Frequency}(X) \times \text{Frequency}(Y)}\]
Unlike confidence, lift is symmetric, meaning the direction of the rule does not matter:
\[\text{Lift}(X \to Y) = \text{Lift}(Y \to X)\]
Importantly, lift values above 1 indicate a positive association between the antecedent and the consequent: the presence of one increases the probability of the other occurring (Tan et al., 2019; Han, Kamber, & Pei, 2012). In our current output, all 18 association rules have a lift greater than 1, which suggests that each rule reflects a meaningful association. The higher the lift, the stronger the relationship between the items. However, since lift is derived from both support and confidence, the thresholds set for these two metrics directly affect which rules are generated and their corresponding lift values. Adjusting these thresholds will therefore influence the rules produced and their relative strength.
Rules on Specific Itemsets
Just as we can set a minimum number of items in an itemset, we can also restrict our analysis to rules involving specific items. In particular, we can specify that a certain item must appear on the left-hand side (lhs) or right-hand side (rhs) of the association rule. For example, to generate rules where “The Matrix” appears on the right-hand side, we can use the optional appearance argument and set rhs to our target movie:
# Apriori Algorithm - Rules for "Matrix, The"
matrix_rules <- apriori(movies_tr,
parameter = list(
support = 0.3,
conf = 0.9,
minlen = 3,
target = "rules"
),
appearance = list(
rhs = "Matrix, The"))
# Print the Results
tibble(lhs = labels(lhs(matrix_rules)),
rhs = labels(rhs(matrix_rules))) %>%
bind_cols(matrix_rules@quality)As expected, only rules that have "Matrix, The" on the right-hand side are generated, since we explicitly specified this condition. The itemsets on the left-hand side can significantly “lift” the probability of "Matrix, The" being selected, with a lift value of approximately 1.5. Based on these insights, we might recommend the movie The Matrix to users who watched Star Wars: Episode IV – A New Hope and Star Wars: Episode V – The Empire Strikes Back.
Redundant Rules
When using the Apriori algorithm to generate association rules, the output often includes all possible rules, many of which may be redundant or simply non-informative.
A redundant rule is one that does not provide additional insight because a more general rule already captures the relevant behavior with the same or higher confidence. For example, suppose we are interested in identifying whether a driver is delinquent. A rule such as “a driver who passes one red light gets stopped by the police” already describes delinquent behavior. If we then add a more specific rule—“a driver who passes two red lights gets stopped”—this does not add new information for our question, since delinquency is already established at the first violation. In this context, the second rule is redundant. However, if the focus of analysis were on the intensity of delinquency (how often or how severely the driver violates rules), then the second rule would no longer be redundant, as it provides additional insight into the degree of misconduct.
Generally, lower thresholds for support and confidence increase the probability of generating redundant rules. Removing these redundant rules results in a more concise, meaningful set of associations, improving the validity of our market basket analysis. From a business perspective, product recommendations should be targeted and relevant. Avoiding unnecessary repetition enhances customer experience and increases the effectiveness of cross-selling strategies.
Let’s identify and remove redundant rules in our current output. Hopefully, the apriori package has this analysis built-in: we can use the function is.redundant(). To demonstrate, we generate a set of association rules with a confidence threshold of 60%, a minimum of 2 items on the left-hand side, and the movie “Matrix, The” on the right-hand side:
# Apriori Algorithm - Rules for "Matrix, The"
matrix_rules <- apriori(movies_tr,
parameter = list(supp = 0.3,
conf = 0.6,
minlen = 2,
target = "rules"),
appearance = list(rhs = "Matrix, The"))
# Print Number of Rules
matrix_rules
# Combine the outputs in one tibble
output <- tibble(lhs = labels(lhs(matrix_rules)),
rhs = labels(rhs(matrix_rules))) %>%
bind_cols(matrix_rules@quality)After adjusting these parameters, we now have 42 rules instead of 5. To check for redundancy, we apply is.redundant(), which returns TRUE for redundant rules and FALSE otherwise. Since TRUE is treated as 1 and FALSE as 0 in R, we can sum the results to count redundant rules:
# Printing the number of redundant rules
matrix_rules %>% is.redundant() %>% sum()[1] 2The output is 2, indicating two redundant rules. Let’s examine these rules by filtering the output using the positions indicated by is.redundant():
# Finding the redundant rules
output[matrix_rules %>% is.redundant(), ]# A tibble: 2 × 7
lhs rhs support confidence coverage lift count
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <int>
1 {Lord of the Rings: The Fellows… {Mat… 0.33 0.868 0.38 1.45 33
2 {Lord of the Rings: The Fellows… {Mat… 0.31 0.886 0.35 1.48 31Although these rules have a lift above 1, they remain redundant:
If the movies The Lord of the Rings: The Fellowship of the Ring and The Lord of the Rings: The Two Towers are selected, then The Matrix is likely to be selected.
If the movies The Lord of the Rings: The Fellowship of the Ring, The Lord of the Rings: The Two Towers, and The Lord of the Rings: The Return of the King are selected, then The Matrix is likely to be selected.
Why are these rules redundant? Let’s select rules containing movies from The Lord of the Rings franchise and sort by lift in descending order:
# Selecting the rules containing "Lord of the Rings"
output %>%
filter(stringr::str_detect(lhs, "Lord of the Rings")) %>%
arrange(desc(lift))# A tibble: 8 × 7
lhs rhs support confidence coverage lift count
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <int>
1 {Lord of the Rings: The Return … {Mat… 0.31 0.886 0.35 1.48 31
2 {Lord of the Rings: The Fellows… {Mat… 0.31 0.886 0.35 1.48 31
3 {Lord of the Rings: The Fellows… {Mat… 0.31 0.886 0.35 1.48 31
4 {Fight Club,Lord of the Rings: … {Mat… 0.3 0.882 0.34 1.47 30
5 {Lord of the Rings: The Two Tow… {Mat… 0.33 0.868 0.38 1.45 33
6 {Lord of the Rings: The Fellows… {Mat… 0.33 0.868 0.38 1.45 33
7 {Lord of the Rings: The Return … {Mat… 0.31 0.861 0.36 1.44 31
8 {Lord of the Rings: The Fellows… {Mat… 0.37 0.822 0.45 1.37 37The first rule is redundant because there is already a simpler rule of higher lift: if a user selects only The Lord of the Rings: The Two Towers, then The Matrix is likely to be selected. The second rule is redundant because there is already a simpler rule of higher lift: if a user selects only The Lord of the Rings: The Fellowship of the Ring and The Lord of the Rings: The Return of the King, then the The Matrix is likely to be selected.
To remove redundant rules, we use logical indexing in R, keeping only non-redundant rules:
# Removing redundant rules from the final output
output <- output[!matrix_rules %>% is.redundant(),]
# Printing output
output %>% nrow()[1] 40The number of rules has decreased by two, confirming that the redundant rules have been successfully removed.
Advantages and Limitations
Market Basket Analysis (MBA) is a simple and effective data mining method for understanding customer behavior and increasing interest in a company’s products. It can confirm intuitive patterns—such as customers who buy a laptop often also purchase a keyboard—validating assumptions and reinforcing business strategies. At the same time, some rules may initially seem surprising or even random. For instance, customers who buy a new laptop might also purchase a bicycle. While this association may appear spurious at first, it could reflect underlying behavior that is not immediately obvious, such as students relocating to a new city and adopting a new lifestyle. This highlights the importance of critically evaluating association rules, combining domain knowledge with statistical metrics like support, confidence, and lift.
Despite its usefulness and easy implementation, MBA has several limitations. Firstly, it identifies correlations, not cause-and-effect relationships, so associations must be interpreted with caution (Han, et al., 2012). MBA also typically ignores quantities, focusing only on whether items are purchased together, which can limit practical insights. Some rules, while statistically strong, may be irrelevant for business decisions or simply confirm what is already obvious, providing little new information, especially in small datasets (Lantz, 2023). Furthermore, most customers may not be responsive to recommendations, so even valid patterns may not translate into actual sales. Finally, in large datasets, MBA can generate a huge number of rules, making it challenging to identify actionable insights. For example, in a supermarket, the sheer number of potentially relevant product associations can make designing effective recommendations and optimizing shelf organization difficult (Agrawal et al., 1994).
To translate the findings of MBA into actionable insights, the focus should be on rules that are both statistically significant and practically relevant. In real-world applications, businesses can use Market Basket Analysis to optimize product placement in physical stores, tailor recommendations on e-commerce platforms, and design targeted promotions or bundled discounts. The ultimate goal is not merely to discover patterns, but to apply them in ways that enhance the customer experience and drive business success.
Recap
Market Basket Analysis (MBA) is a simple and effective data mining method for understanding customer purchasing behavior and improving product recommendations. It helps businesses identify patterns in transactions, which can be used for better product placement, cross-selling, and targeted promotions. To apply MBA in practice, we often use the Apriori algorithm, which efficiently finds association rules by calculating support, confidence, and lift, even in large datasets. While MBA can uncover both intuitive patterns and less obvious associations, it has limitations: it shows correlations, not causation, ignores purchase quantities, and can generate too many rules, some of which may be redundant or not useful. The key is to focus on rules that are both statistically meaningful and practically relevant, so that patterns can actually inform decisions and improve the customer experience.